By Doug Rufer, BSBA, RT(R)
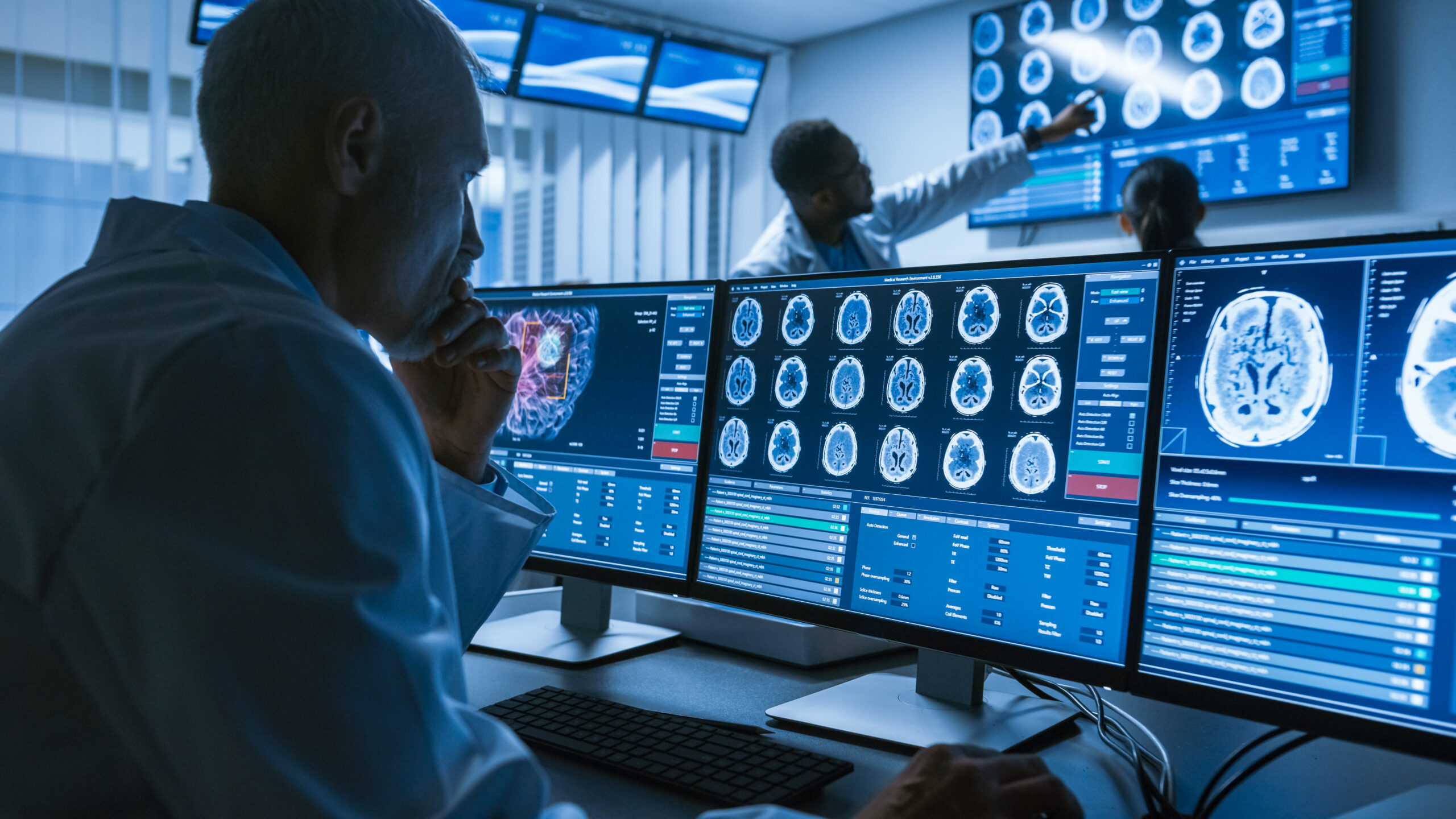
Artificial Intelligence (AI) can profoundly advance healthcare and we’re just beginning this journey, as so much has yet to be discovered! But to advance care, we must do things differently, change our ways of the past. It is no longer ok to keep repeating the same things over again and expect different results. One area that must change is for organizations to implement and enforce a strong data governance policy. Without data governance and a focus on data standardization, you will end up with a lot of data that provides little value. At Enlitic, we have a saying: “content without context is just data but adding context to that data provides actionable information from which you can gain valuable insights to drive meaningful decision making in the critical care setting”.
If you are a healthcare organization focused on using the data you possess to drive future insights, then most likely you are considering (or have) a Data Lake. But if you’re not careful, you may end up with data that doesn’t provide you with the insights you were planning for. In fact, you may be harboring a Data Swamp, and no one wants their beautiful lake view to become muddy and overgrown and infested with gators, so keep reading to learn why getting control of your data will keep you out of the swamp and help drive better clinical insight!
Data Lake vs. Data Swamp
A Data Lake is a large storage repository that contains structured, semi-structured, and unstructured data in its native format. A Data Lake will continually take new data on an on-going basis to build a repository of all your information without constraints on file size, structure, or hierarchy while being tagged with a unique identifier and metadata tags. A Data Lake is different from a Data Warehouse, where a Data Warehouse stores files in hierarchical folders and consists of mostly structured business process data that’s been optimized for data retrieval. Data Lakes offers better analysis of data because data does not need to be mapped to an enterprise data model. It’s a more robust view of your data for data scientists[1].
A Data Swamp on the other hand is an unmanaged Data Lake that is either inaccessible to its intended users or provides little value. Data Swamps occur when adequate data quality and data governance measures are not implemented.
When a Data Lake holds too much data in a poorly organized manner without suitable metadata management and a reliable data governance, relevant data becomes increasingly difficult to find. The information content of the Data Lake actually decreases even as new data is continuously being added. Without a good life cycle management process on your data, this can “silt” up your Data Lake as well. As time goes on, your data will begin to lose its relevance over time. Additionally, long-term data with incorrect time stamps can lead to data that cannot be found or evaluated, further decreasing the value of the data you are storing[2].
Data Governance and Data Fluency
Healthcare IT solutions have used data standards for decades, as quite a few exist (FHIR, HL7, DICOM, ICD-10, etc). But these data standards have variability, and to date, no one has agreed upon applying insight to those data standards. Data can be exchanged but can the receiving system understand the context that the data is being transmitted in. In other words, does the data have context that any system that receives it, understands exactly how to act upon it?
Global standards exist. Call to China from the US on any phone and your call will go through. Aggregate your financial information from multiple locations into a single App. Even download music from any location and you can play it on your Apple device. What exists is a standard that has strong data governance.
If you want to read a good article on how data fluency can impact healthcare, check out this blog from Enlitic where they define data fluency as the ability to communicate data insights while understanding the context and methods used to process the information. That is, understanding what went into making a clinical decision.
For data fluency to be useful, providers need to be able to turn massive amounts of raw data into actionable information, and that can only be accomplished through better data standardization and better context to the data. Proper data standardization will ensure that all information that is necessary is applied to the data so that proper context can be applied. When a researcher searches for a complex query, the right information will present from your Data Lake, hence your data will be fluent. Miss the standardization portion and your researchers are fishing in a swamp.
Data to Insight
So how does data governance, data standardization, and data fluency relate to real world clinical challenges? By removing siloed barriers that exist today.
Medicine is advancing at a rapid pace. We are discovering insights today that were only dreamed of a few years ago, but this begs the question if we are truly doing enough? The impact that precision medicine can have on individuals – or population health has on a given condition within a population are only possible with better data and insight.
Consider this: does a women being treated for stage 2 breast cancer in rural Montana deserve a lower quality of care than a person with a similar demographic living in the greater Houston area? Health inequity is real – but it can be solved with better insight. The woman in rural Montana should be receiving the same quality of care with the same clinical insights as the person living in Houston who has access to one of the leading organizations for cancer care – but that’s not the case. Why? Because insight that compares the woman’s clinical history in Montana cannot easily be matched with insight from other similar patients with the same condition and economic and clinical history from around the world. Data fluence – and access to the insight – solves the problem. First you standardize the data, then you apply clinical insight, then you make that data searchable to others – anonymously, of course – then you begin to change patient outcomes at scale.
Stay Out of the Swamp!
Seven hundred and fifty million radiology exams are performed annually in the US alone, generating petabytes of data faster than you can believe. But locking that data into archive silos to only be used to compare it with another study in the future is missing a huge opportunity. Our industry needs to capture and store all data, ensure it is properly standardized, and accessible in a method that allows comprehensive analysis. Only then can we connect that data with other organizations around the world so they too can benefit from the same insight, eliminating health inequity. Better data will lead to better insight and that will bring far better outcomes than we see today – most likely at a significantly reduced cost. Imagine how powerful our collective insight can be once we open the gates, avoid the swamp, and venture into a Data Ocean, only then can healthcare truly be reimagined.
If you would like to learn more about how you can start your journey to better data governance and standardization, check out Enlitic at www.enlitic.com.
[1] Taylor, David. “What Is Data Lake? It’s Architecture: Data Lake Tutorial.” Guru99, 5 Jan. 2023, https://www.guru99.com/data-lake-architecture.html.
[2] Lauer, Christian. “What Is a Data Swamp?” Medium, CodeX, 28 Dec. 2021, https://medium.com/codex/what-is-a-data-swamp-38b1aed54dc6.