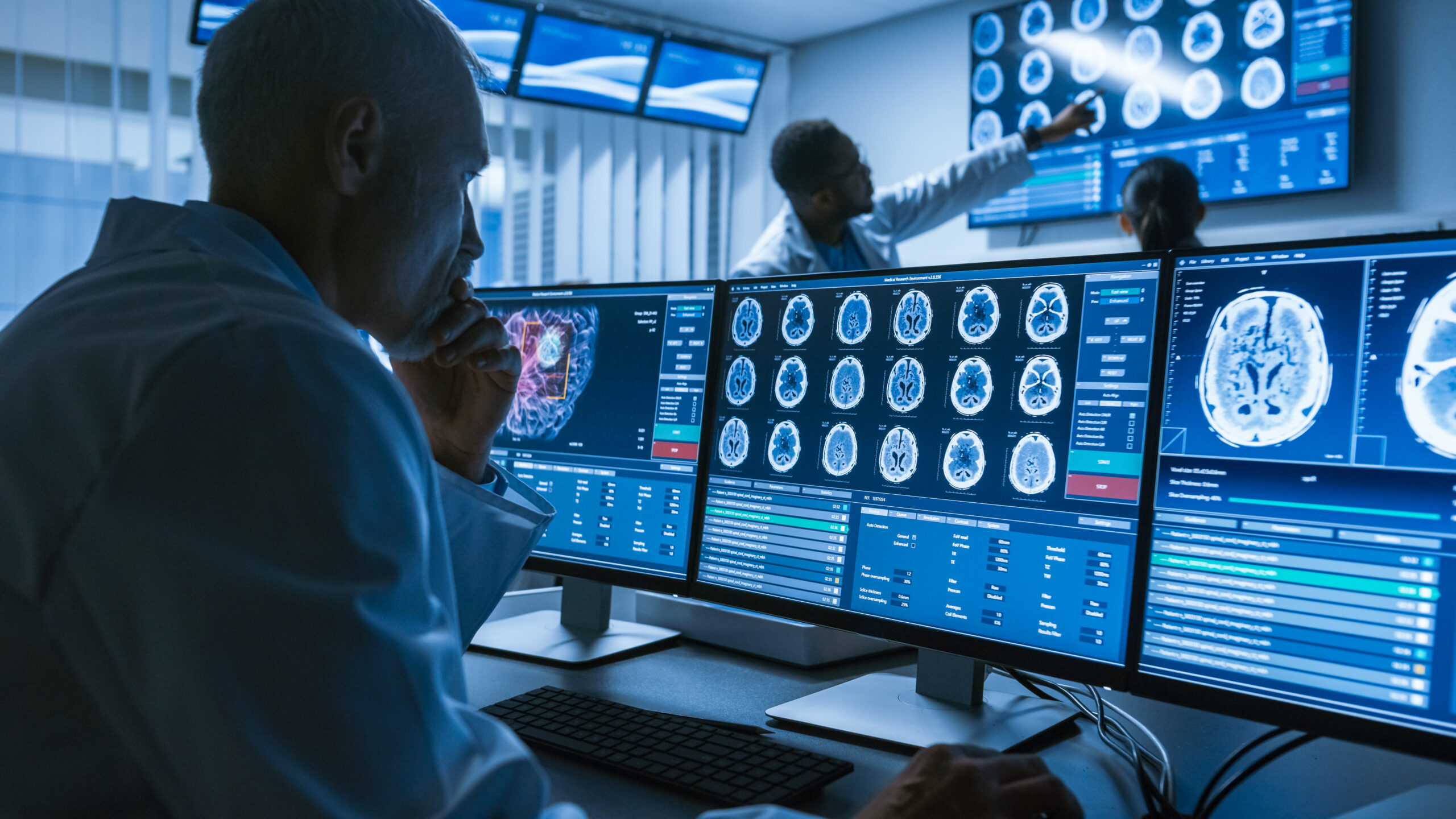
The availability of high-quality data is indispensable for driving advancements in diagnostics, treatment, and patient care. Researchers rely on accessing and analyzing vast amounts of data to uncover insights that can improve outcomes and enhance medical practices. However, the choice between utilizing a medical imaging registry or database can profoundly influence the efficiency and effectiveness of research endeavors in this specialized field.
Medical imaging registries and databases serve as invaluable repositories of patient images, clinical data, and research findings. Registries often focus on aggregating data from specific patient populations or disease cohorts, facilitating longitudinal studies and observational research. In contrast, databases offer greater variability by storing diverse datasets, enabling researchers to explore various imaging modalities, patient demographics, and clinical outcomes.
A significant challenge that researchers encounter when working with medical imaging data is finding and preparing the data they need. Without standardized labeling conventions and robust search functionalities, researchers are often burdened with the arduous task of preprocessing and organizing data before they can begin their analysis. This time-consuming process not only delays research projects but also introduces the potential for errors and inconsistencies, undermining the reliability of study findings. In fact, 80% of the researchers’ time is spent organizing and cleaning data. Also, 57% report that this process is the least enjoyable part of their job.
Now, envision a scenario where researchers have access to standardized, searchable medical imaging data without the need for extensive preprocessing. With the tools Enlitic offers, this vision can become a reality. By leveraging anonymized data with standardized labels and descriptions and search functionalities, both medical imaging registries and databases can empower researchers to dive straight into their analysis.
Enlitic reviews the pixel and metadata of an image using artificial intelligence to determine such things as is contrast present, what modality was used, what is the laterality. This information is stored in a common data model upon which an inference engine, intelligence that can deduct from the image review how the study and series should be labelled, relabels the descriptions in a consistent and standardized way.
So, what could healthcare researchers achieve if they were liberated from the burden of data preprocessing? The possibilities are profound. Researchers could expedite their processes and skip the manual, time-consuming methods of data organization and labeling. Their quality control efforts could be greatly reduced allowing for the data prep stage of their study to be reduced significantly.
The imperative of standardized, searchable data cannot be overstated in healthcare research, particularly in the domain of medical imaging. Whether leveraging registries or databases, ensuring the accessibility and organization of medical imaging data is paramount for driving meaningful advancements in patient care. By investing in robust data infrastructure and embracing the advanced technologies Enlitic possesses, we can realize the full potential of medical imaging data and usher in a new era of precision medicine and personalized healthcare.
Learn more! Schedule time with us at HIMSS and visit booth 5851!