AI-Enabled DICOM Data Migration: Streamlining Healthcare Data
In the second part of our three-part series on AI-enabled DICOM data migration, we delve into the critical steps of data extraction, normalization, and cleaning. These processes are essential to ensure that the new system is ready to operate with the best possible data quality. The journey begins with the extraction of data, where it is crucial to normalize DICOM files. Ideally, all Picture Archiving and Communication Systems (PACS) and Vendor Neutral Archives (VNAs) should operate on the same regulated and approved DICOM formatting. However, due to the complexity of DICOM tags—some images can have over 10,000 tags—errors can occur. Newer systems are more DICOM-compliant and less tolerant of noncompliant data, making normalization a vital step.
Normalization and Reconciliation
To address these challenges, LAITEK performs a comprehensive check against the most common DICOM errors to correct and normalize the data before processing it further. This includes a 7-point data check that scans for inconsistencies between Radiology Information Systems (RIS) and DICOM files. The elements checked include Medical Record Number, Accession Number, Patient Last Name, Patient First Name, Date of Birth, Patient Sex, and Study Date. This process is crucial for preventing data loss or incorrect categorization during migration, especially when patient information has changed over time. For instance, if a patient’s name has changed, older studies might not reflect the current Electronic Medical Record (EMR) data, potentially leading to lost or misaligned studies in the new system.
In cases where studies cannot be reconciled, LAITEK places the files into an archive server (ATRIUM) for the client to review and reconcile. This step ensures that all data is thoroughly examined before proceeding to the next stage.
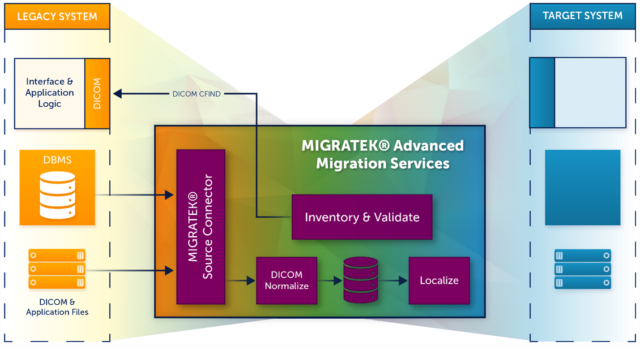
Data Localization and Integration
Once the data has been normalized and reconciled, the final stage before migration involves localizing the data. This process is necessary because old and new systems, even from the same manufacturer, may handle data differently. For example, during acquisitions like St. Francis Evanston being acquired by Advocate Medical, differences in patient ID formats must be reconciled. LAITEK works with clients to understand how their new system operates, ensuring seamless integration by addressing these differences according to client specifications.
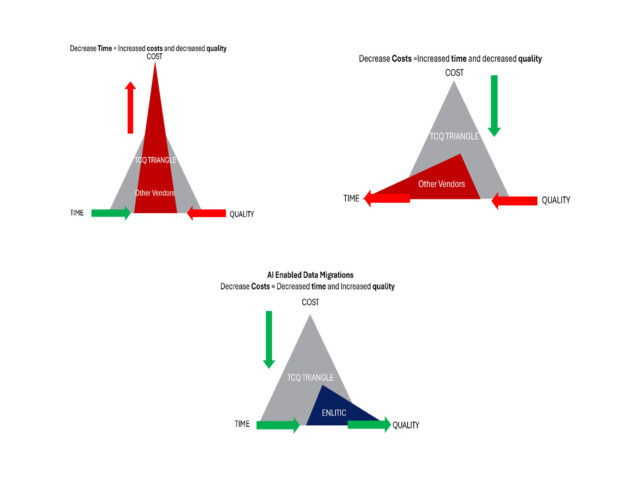
Real-World Applications
Real-world examples illustrate the benefits of AI in data migration. For instance, when hospitals merge with larger networks, AI can help combine their different patient ID systems. This was the case with St. Francis Evanston, which was acquired by Advocate Medical. The hospital had to adjust its patient IDs from a 12-digit alphanumeric format to a 16-digit numeric format used by Advocate. AI helped reconcile these differences, ensuring a smooth transition.
The localization process also involves updating outdated terminology to maintain consistency between old and new studies. For instance, an order for a chest X-ray might have been coded as “Chest PA Lat” in the past but is now coded as “Chest 2 Views.” By updating such terms, LAITEK ensures that studies are not lost during migration and can be easily found by technicians using current terminology. This is where AI-enabled data standardization significantly speeds up the migration process. AI automates manual tasks at scale with minimal human involvement, improves data quality by ensuring it is correct and consistently labeled, and reduces costs by lowering the time required for migration and system configuration.