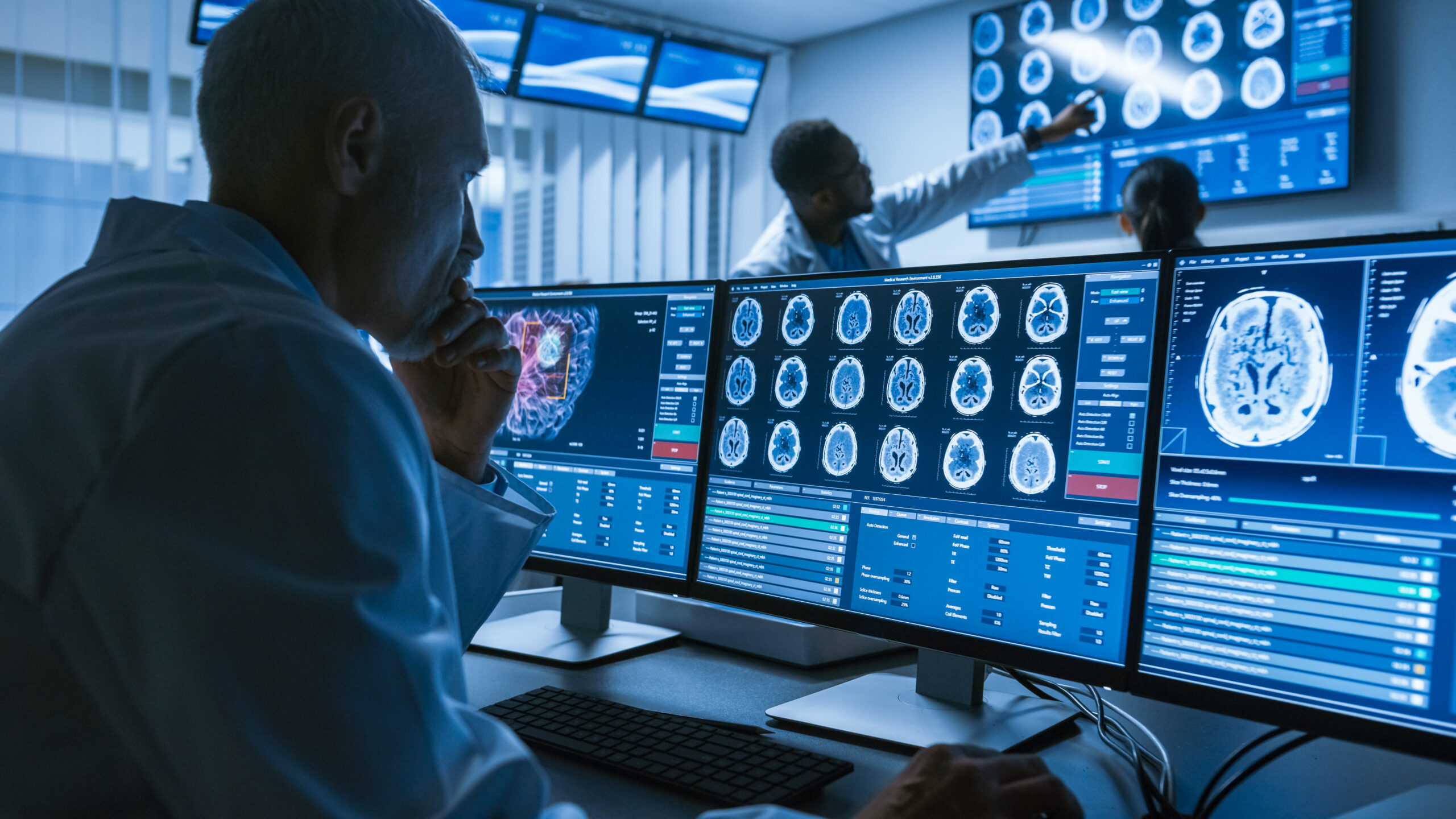
Medical images contain some of the most sensitive protected health information (PHI). PHI in medical images can include a patient’s name, date of birth, medical record number, and other identifying information. Medical images are often used to make diagnoses and determine appropriate treatment plans, making them a valuable target for cybercriminals. It is essential to keep PHI secure to protect patient privacy and avoid legal consequences.
The Importance of PHI Data Security
The healthcare industry is one of the most targeted industries by cybercriminals due to the value of the information they hold. The importance of PHI data security in medical images cannot be overstated. Medical images are stored electronically in Picture Archiving and Communication Systems (PACS) and transmitted to healthcare providers over networks. Without adequate security measures in place, this data can be accessed by unauthorized individuals, putting patient privacy at risk.
Medical image breaches can have severe consequences, including identity theft, medical fraud, and even blackmail. The consequences of a medical image breach can be devastating for patients and hospitals, leading to physical, emotional, and financial harm.
The Issues Professionals Face with Current Techniques
Despite the importance of removing PHI from medical images, there are still some challenges and issues with the current methods of anonymization and de-identification. Some of the fundamental issues include:
Incomplete removal of PHI: The removal of PHI from medical images is often a manual process, which can be time-consuming and prone to error. Incomplete removal of PHI can occur when the person doing the anonymization or de-identification misses certain identifying features such as tattoos, scars, or other unique physical characteristics.
Re-identification risk: Even after removing PHI from medical images, there is still a risk of re-identification. Researchers have shown that even subtle changes to medical images can be enough to re-identify patients in some cases. This is especially true if the images are combined with other publicly available information.
Loss of clinical information: Some methods of anonymization or de-identification can result in the loss of important clinical information that could be useful for research or treatment purposes. For example, removing patient demographics and clinical data from medical images could limit the usefulness of the images for certain types of research.
Lack of standardization: There is currently a lack of standardization in the methods used to anonymize and de-identify medical images. This can lead to inconsistent results across different datasets and make it difficult to compare results across different studies.
Cost: Some methods of anonymization can be costly, especially for large datasets. This can make it difficult for smaller research institutions or hospitals to implement effective anonymization and de-identification practices.
Time-consuming: The process of anonymizing or de-identifying medical images can be time-consuming and labor-intensive. This can slow down research and clinical workflows, leading to delays in diagnosis and treatment.
It is essential to address these issues and use more effective and efficient methods of anonymizing and de-identifying medical images to protect patient privacy while maintaining clinical utility. Enlitic has developed standardized protocols and software to improve the accuracy and efficiency of the process, reducing the risk of incomplete removal of PHI and re-identification.
Complete Protection with Retained Clinical Information
Enlitic solutions protect patient PHI while creating and enriching normalized clinical data. Studies that get standardization using AI (Artificial Intelligence) with ENDEX™ come out with a clinically relevant description using a normalized universal ontology. The images can then get anonymized or de-identified with ENCOG™. When this occurs, PHI gets removed from the images using Natural Language Processing (NLP) and Computer Vision (CV) like that used during standardization. This allows for complete removal of PHI in all locations such as metadata, pixel data and all image tags. Information is hashed and dates are shifted to retain important longitudinal data and relationships. ENCOG eliminates the need to relabel, saves time and costs, and reduces risks associated with various freeware, manual removal, or other software techniques.
Using Software Powered by AI to Anonymize and Deidentify Medical Image Data for Proper PHI protection
PHI data protection in medical images is crucial to ensure patient privacy and avoid negative consequences. However, the current methods of anonymization and de-identification present several challenges and issues. It is vital to address these issues and use more efficient and effective methods to protect patient privacy while maintaining clinical utility. Enlitic’s solutions leverage AI to find PHI in places that may not be apparent to a user or are not part of the routine review of data. Often there are a set number of fields that are deleted blindly, regardless of the content, in which case valuable clinical data is lost needlessly. This approach reduces the risk of incomplete removal of PHI and re-identification while saving time and costs. Overall, a standardized and efficient approach to PHI data protection and security is crucial to ensure patient privacy and improve clinical outcomes.
Interesting Statistics:
NNT research on medical image archives, or PACS, connected to the public internet and located in the US, found over 170 identified systems left unprotected.
According to Schrader, 81 of these entities are new from the initial 2019 reports, and 89 are old or previously found by his research. Of the 89 entities, 69 received a responsible disclosure via email in December 2019.
Alarmingly, however, those older systems added 700,000 exams in the last year.
Schrader also found five systems with more than 400,000 exams from an estimated 100,000 patients per each system, in addition to 14 million exams that included patient names, dates of birth, exam dates and descriptions, physician names, patient IDs, institutions, partial SSNs, and more sensitive information.
Researchers from Germany’s Greenbone Networks have seen a 60 percent increase in the number of PACS medical archive images left exposed online, with US patients most affected by the breach.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9335165/
Healthcare data breaches have quickly become the costliest of attacks across all economic sectors, and radiology groups and imaging centers have been increasingly affected in the form of ransomware, denial of service attacks, and lawsuits brought by affected patients.